总字数:约10000字,阅读时间:约10分钟
在最开始接触深度学习的时候,很经常使用MatConvNet。主要是因为里面的预训练模型比较丰富,在fine-tune的过程中能获得比较好的结果,很适合新手使用。但是随着对深度网络越来越深入之后,很多就需要自己去设计层结构,损失函数,规则项等等,这个时候MatConvNet就显得力不从心了。而keras的出现就大大简化了这一过程,良好的接口让构建模型简单快速,而且可扩展性强。对于需要深入底层的实现,也可以使用TensorFlow或Theano来实现,确实是一个很好的工具。
不过虽然Keras上面也有很多预训练好的模型,可以用来进行fine-tune,但是其丰富程度远没有MatConvNet的多。思来想去,决定自己写一个函数来实现MatConvNet模型对Keras模型的一个转变。
读取mat文件
在Python中,要读取Matlab的.mat文件需要借助Scipy库中的io模块。在Scipy.io中有一个loadmat函数,可以实现对.mat文件的读取。注:本文以vgg-face模型为例进行说明。
|
|
这里有两个参数,squeeze_me是用于将Matlab中空的二维结构压缩成一维结构,因为Matlab中常出现(1, N)的数组,所以直接读取,在Python也会保留二维结构。但实际上它并没有任何意义,反倒会因为需要做两层索引而增加编程负担,而被压缩成一维之后在后续操作中会更为便捷。struct_as_record默认是True,在这种情况下struct类型数据会被存在dict结构中。当把这个设置成False时,所有的struct数据会被当成属性,调用起来比较直观。
前期处理
在vgg-face.mat中,只有layers里面的内容是涉及到网络结构的,而meta中的内容是关于数据集的一些信息,在这里我们暂时用不上。
这里是我们需要用到的模块。
|
|
然后,我们可以定义一个函数,来专门完成模型的转换功能。
|
|
mat_model_layers指的是MatConvNet模型中的layers数据,传入的时候只需要传入这个参数就可以了。input_shape是模型的输入大小,这个是在meta中,所以我们也单独把它提出来,作为参数传入。only_architecture是指只保留结构,而不导入权重,在个别情况下,我们可能只需要结构,而不需要预训练模型。
函数接口定义完之后,我们就可以开始进入细节了。首先做一些准备工作。
|
|
我们这里使用泛型模型的API来构建Keras模型,这样的好处是以后遇到了新的结构,可以很好的做扩展。其次是pooling_dict和activation_set,我们事先将pooling层类型和activation类型放置在这两个结构之中,然后内部需要调用时直接从这里找,这样在之后需要扩展的时候直接将新的层结构加到这里面就可以了。最后is_flatten是用来判断是否被flatten,在MatConvNet中,没有flatten的操作,它直接用conv层来表示全连接层,最后出来的结果用squeeze函数来压缩冗余的维度,但是在Keras并不能这样做,所以我们需要判定一下在全连接层前是否被flatten,如果没有的话我们需要添加Flatten层
构建层
构建层是整个函数的核心。先将所有代码都放上来,在后面我将会一步一步详细说明实现逻辑。
|
|
整体代码逻辑并不复杂,但是涉及一些细节处理的问题,需要详细说明一下。我们需要对每一层进行迭代。进入循环后,获取层的类型和层的名字,在MatConvNet中,层类型和层名在type和name两个属性中,这里我们可以直接获取。
|
|
获取到这两个参数之后,开始进行验证。如果是conv类型,则是MatConvNet中的卷积层,这个时候对应的层中,会有weights属性,这里就是我们需要的权重。weights是一个列表,第一个元素是filter的权重,第二个元素是bias的值。我查阅了MatConvNet的文档,里面给出他的权重是按照HWD*D’的结构定义的,分别代表高度、宽度、深度和卷积核数。在Keras中,卷积层只需要给定卷积核的高度、宽度和核数。深度在底层会自动进行匹配,所以我们只需要将这几个值切片出来,然后创建卷积层,并传入相关权重即可。
但是,这里有一点需要格外注意,因为MatConvNet中没有单独定义全连接层,其直接使用卷积层作为替换,最后结果使用squeeze函数来压缩冗余的维度。而这两种层唯一的区别在于name属性中,卷积层为’conv’开头的字样,如’conv1_1’,而全连接层以’fc’开头的字样,如’fc8’。所以这个时候我们就以name属性作为判断依据来判定是否为全连接层。
|
|
值得一提的是,在MatConvNet中,存在stride和padding属性来确定遍历情况。但是在Keras中却没有,Keras只提供了三种border_mode(’valid’:只在特征内遍历,不进行扩充。’same’:保持特征大小不变, ‘full’:遍历所有元素,卷积核超出特征边界的部分设置为0)。如下图所示(下图来源于深度学习Keras群@情笔M医学影像)。
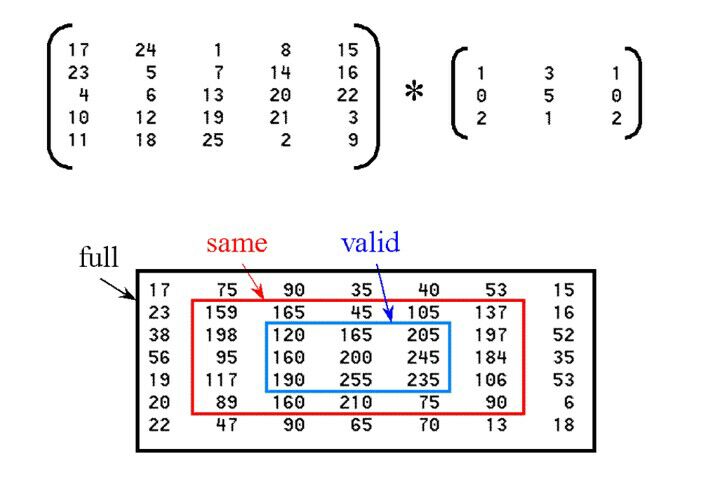
而VGGFACE模型中,所使用的卷积层均为stride=1,padding=1,即为Keras中的same模式,所以我们定义卷积层的时候直接用这个border_mode即可。
回过头来,如果是全连接层,我们就需要做一个判定,看是否被flatten。这里是MatConvNet设计上的一个区别,因为没有flatten层,所以它只能采用类似于全卷积的方法,定义一个卷积核与特征维度相同的卷积层,使得最后出来的特征是单维的。而这一层实际上是一个全连接层,所以MatConvNet使用’fc’字样开头的名字来定义name属性,也就是说这一个包含卷积核的全连接层。而Keras中因为有Flatten层,所以不需要考虑这么多细节问题。但是在这里,我们就需要依照MatConvNet的结构,对第一个遇到的全连接层,再多定义一个卷积层,并且将border_mode设置为valid(相当于stride为1)。
其次还有一个问题是权重维度,因为对于全连接层而言,权重维度为2,但是对于卷积层而言,则是4。所以对于其后的全连接层,它是按照input_node*output_node的结构来定义的,所以我们取权重的第二维大小作为全连接层的节点数即可。最后对未实现的结构抛出异常。
|
|
然后就是对pooling层和activation层的一个添加,这部分比较好理解。由于我们事先将pooling层类型和activation类型添加入了pooling_dict和activation_set中,所以检测和添加过程都比较简单。需要提一下的是,Keras中的pooling层需要给出pooling size和stride,这两个参数分别对应MatConvNet中的pool和stride属性,其中stride属性在MatConvNet中是一个数,因为它在两个方向上的遍历步长都是一样的,而Keras需要分别给出,所以我们多复制一个就好了。
最后对未实现的层抛出一个异常。如果之后又新的模型出来,需要转变新的层结构,只需要在这里的分支结构添加一个新的分支即可。
|
|
最后,创建用输入和输出创建整个模型并返回,就完成了。
‘’’
model = Model(input=inputs, output=x)
return model
‘’’
测试
在MatConvNet中,给了每一个模型的测试程序,这里我们就仿照着他的测试程序,写一个Keras版本的,对了,在meta中,包含了整个模型的元信息,包括输入大小,训练集统计数据,标签表述等等。需要的话可以去对应的.mat文件中查看。
‘’’
import os
from PIL import Image
if name == ‘main‘:
mat_model = loadmat(os.path.join(‘..’, ‘matconvnet_model’, ‘vgg-face.mat’), squeeze_me=True, struct_as_record=False)
model = convert_model_from_matconvnet(mat_model[‘layers’], input_shape=(224, 224, 3))
im = Image.open('Aamir_Khan_March_2015.jpg')
im = im.crop(box=(0, 0, im.size[0], 250))
im = im.resize(size=(224, 224))
im = np.array(im, dtype=np.float32) - mat_model['meta'].normalization.averageImage
score = model.predict(np.array(im)[np.newaxis, :])
idx = np.argmax(score)
print(mat_model['meta'].classes.description[idx])
‘’’
最后输出结果。
|
|